
Dans cette section nous allons étudier l’architecture et la microarchitecture des GPUs modernes : donc examiner les cœurs SIMT qui implémentent le calcul et le système de mémoire GPU.
Source: General-Purpose Graphics Processor Architecture
Aujourd’hui les GPUs exécutent des dizaines de milliers de threads concurrents, donc il est nécessaire d’avoir une architecture GPU qui puisse tenir ce nombre de threads. On pourrait donc se dire que le système de cache peut être inutile car il y a déjà des emplacements mémoire sur le GPU qui offrent un accès très rapide, mais la mémoire cache GPU permet de réduire le nombre d’accès hors-GPU, donc par exemple sur la RAM (mémoire vive) ou le DD (Disque Dur) (mémoire virtuelle).
Source: Basic Concepts in GPU Computing, Hao Gao
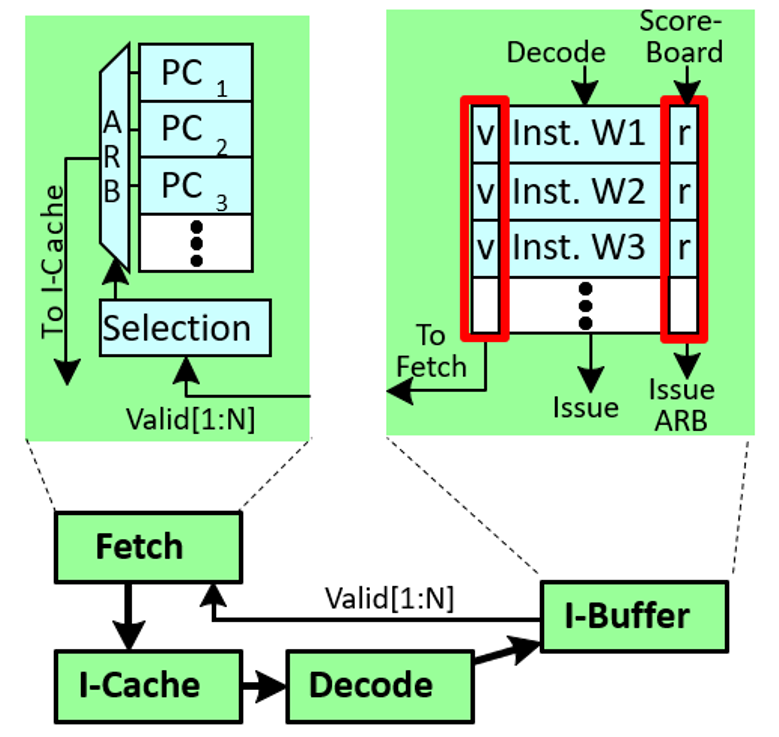
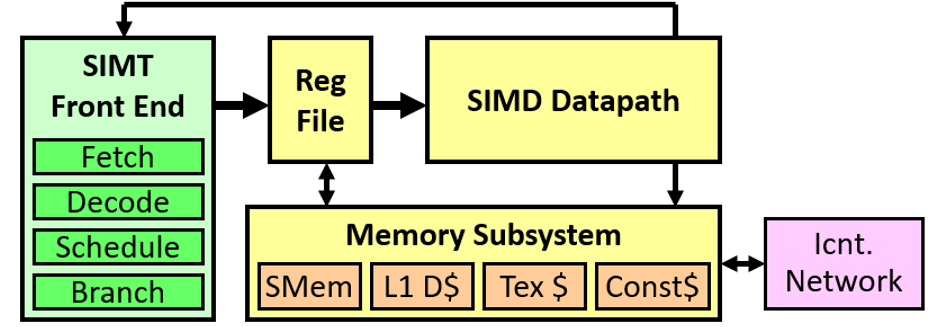
Comme le CPU, le GPU exécute une instruction dans un pipeline. Le pipeline GPU peut être divisé en 2 grandes parties : le SIMT front-end et le SIMD back-end. Ce pipeline GPU consiste en 3 boucles qui agissent ensemble : IFL (Instruction-Fetch Loop), IIL (Instruction-Issue Loop) et RASL (Register-Access Scheduling Loop).

Source: General-Purpose Graphics Processor Architecture
Source: GPU Computing Architecture, Tor M. Aamodt
Source: GPU Computing Architecture, Tor M. Aamodt
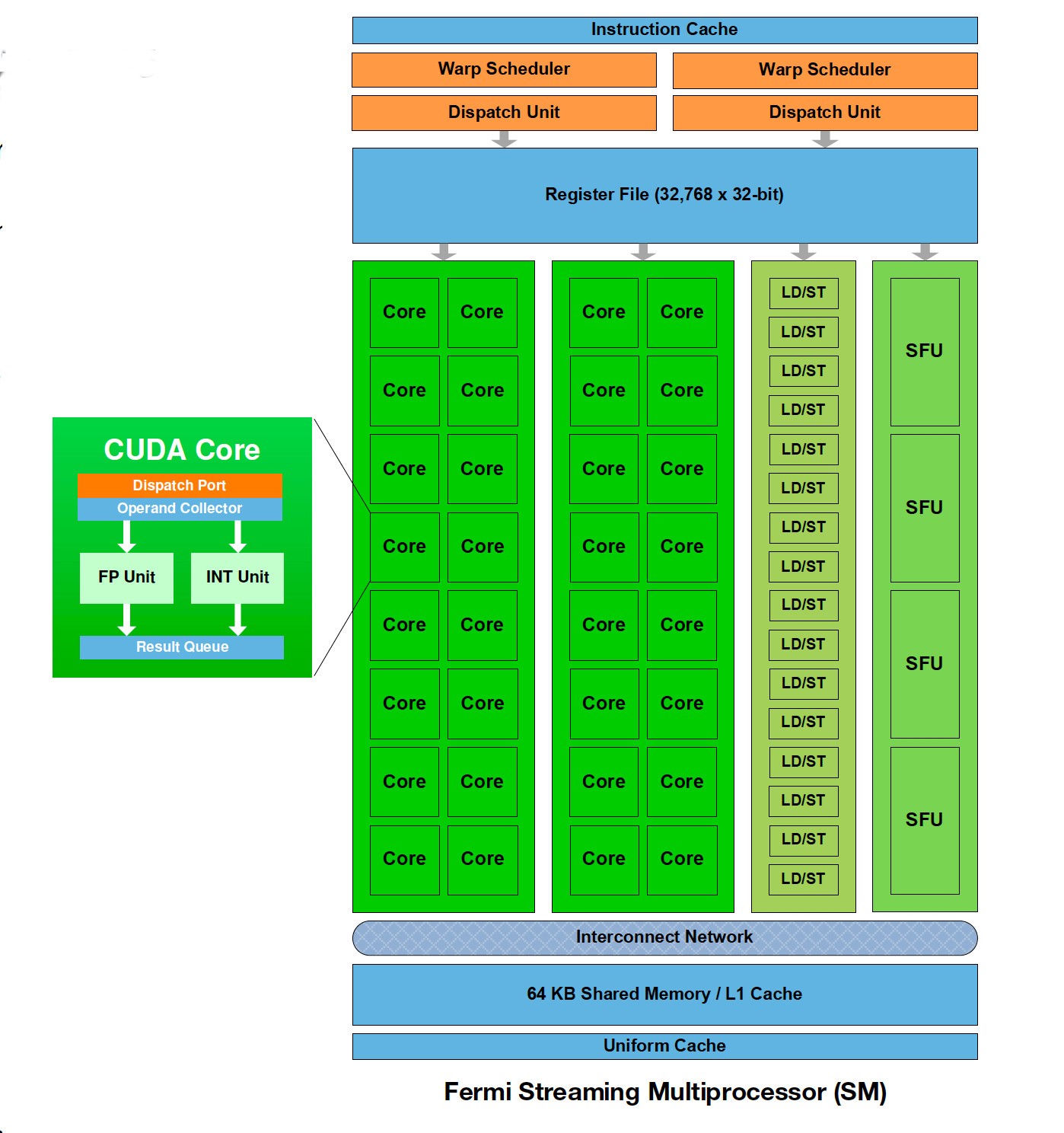
Considérons une seule boucle. A chaque cycle, le hardware sélectionne un warp, l’IP/PC (Instruction Pointer / Program Counter) du warp doit accéder à la mémoire de l’instruction pour trouver la prochaine instruction (comme dans un CPU). Une fois l’instruction fetch, l’instruction est décodée pour comprendre ce qu’elle est (son opcode), et ce qu’elle utilise (les registres) à partir du fichier de registre (qui fait partie de l’operand collector). En parallèle lorsque nous lisons le registre de fichier, les valeurs du masque d’exécution SIMT sont déterminées, pour décrire brièvement ce process, c’est ce qui va aider les threads dans leur flow de contrôle, car comme nous le savons, tous les threads n’ont pas le même flot de contrôle. Une fois que nous avons toutes les informations du masque d’exécution et des registres sources, l’exécution procède en une seule instruction avec plusieurs données (SIMD). Alors il faut savoir qu’aujourd’hui, et c’est le cas dans plein de types de processeurs (par exemple ceux qui sont faits pour calculer les informations réseaux), il y a un SFU (Special Function Unit) qui est fait pour calculer plus rapidement certaines fonctions, par exemple une fonction cryptographique comme SHA-1, il y a aussi des unités de Load/Store, des FPU, IFU (Integer Function Unit), et, comme dans l’architecture Volta de Nvidia, un cœur Tensor (Tensor Core) qui permet par exemple des opérations rapides sur les matrices. Généralement ces ALU se groupent par nombre de threads dans un warp (32 pour Nvidia et 64 pour AMD), mais ce n’est pas nécessairement le cas, par exemple si on les regroupe par 16 unités, nous pouvons augmenter la fréquence de ces unités (ce qui augmente aussi la consommation d’énergie) et de pipeliner leur exécution ou augmenter la profondeur du pipeline.
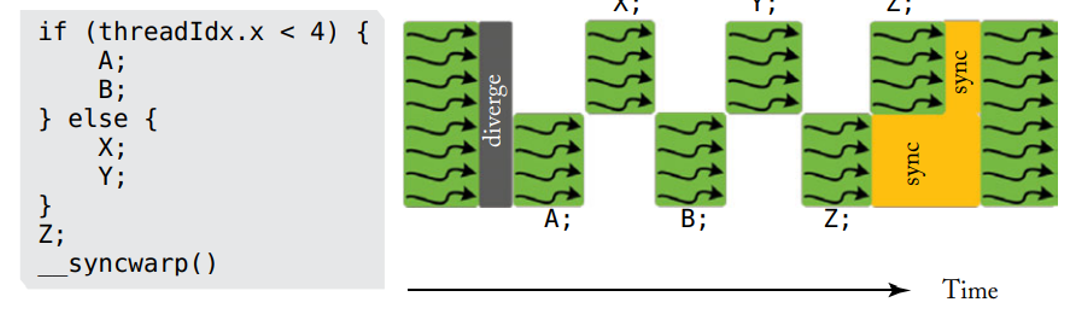
Une fonctionnalité clefs des GPUs moderne est le modèle d’exécution SIMT. Le but de ce modèle est de donner au programmeur l’illusion que chaque thread s’exécute de manière indépendante. Et dans nos GPUs modernes, ceci est fait par la combinaison d’une unité de prédiction traditionnelle et d’une pile de prédicats de masques qui se réfère à la SIMT Stack. Cette combinaison aide l’exécution SIMT dans 2 situations : le flow de contrôle imbriqué, donc lorsque le flow de contrôle est dépendant d’un autre, et la seconde situation aide à sauter des calculs pendant que tous les threads d’un warp ne prennent pas un chemin de flow de contrôle, ceci aide à ne pas calculer les divergences de certaines branches.
La pile SIMT contient un registre TOS (Top Of Stack) qui représente le haut de la pile avec 3 entrées : la re-convergence : c’est-à-dire une fois que les threads sont passés dans leur flow de contrôle respectifs, ils se regroupent, la prochaine divergence et le masque, le masque est défini par un ensemble de cardinal égal au nombre de threads, et de 0 et 1.

Source: General-Purpose Graphics Processor Architecture
Ici le 4è thread part dans l’instruction F, et les 3 autres dans B. Nous allons maintenant étudier le SIMT deadlock et des architectures sans pile SIMT, comment notre cœur SIMT fonctionne lorsque nous avions potentiellement des problèmes de synchronisation, comme par exemple un thread qui est au point de re-convergence alors que d’autres sont encore dans les flots de contrôles de divergence.
Pour introduire le problème SIMT deadlock : la ligne A initialise une variable partagée, un mutex à 0 pour indiquer que le lock est disponible. Sur la ligne B, chaque thread d’un warp exécute l’opération atomicCAS (opération Compare-And-Swap) sur l’adresse mémoire contenant le mutex. Logiquement, dans un CAS, on doit d’abord lire le mutex et le comparer au second opérande, ici 0. Si la valeur du mutex est 0, alors le CAS met à jour la valeur du mutex par le troisième opérande, ici 1. Donc on sait qu’on aura plusieurs accès mémoire, puisqu’ils sont concurrentiels, ils seront sérialisés, donc un seul thread verra la valeur du mutex à 0, et les autres le verront à 1 puisque la valeur aura été swap par le premier thread. Dans la pile SIMT nous savons qu’un seul thread prendra un flot de contrôle différent puisque les autres threads devront surement attendre que le mutex soit à 0 pour exécuter les instructions suivantes. Imaginons le code suivant :
A : *mutex = 0
B : while ( !atomicCAS(mutex, 0, 1)) ;
C : // Section critique
atomicExch(mutex, 0);
La section C est un point de re-convergence, mais chaque thread ira dans cette section de façon séquentiel : il n’existe pas 2 threads qui vont exécuter en même temps les instructions de la ligne C. C’est le SIMT deadlock : chaque thread est dépendant de l’autre. Comme solution à ce problème, nous avons le Barrier Participation Mask (BPM), c’est un masque qui va traquer quel thread d’un warp participe à un SIMT deadlock, à une barrière de convergence, quel thread est bloqué, et pour savoir quel thread arrive à un état de barrière de convergence, il y a le champ Barrier State (BS). Enfin, pour traquer les threads il y a aussi le Thread State (TS) qui dit pour chaque thread d’un warp, quel est son état : prêt à exécuter, bloqué à une barrière de convergence ou fini.

Source: General-Purpose Graphics Processor Architecture
Il y a plusieurs instructions qui vont permettre la détection du SIMT deadlock : ADD, WAIT et YIELD. A chaque divergence on exécute ADD, à chaque re-convergence on exécute WAIT. YIELD est un cas assez spécial car spéculatif donc nous n’en discuterons pas. Ces instructions ADD et WAIT changent le BS qui changent le BPM et qui permettent de traquer les SIMT deadlocks.

Source: General-Purpose Graphics Processor Architecture
Il faut toujours comprendre que ce sont les architectures qui définissent les différentes solutions, par exemple pour l’architecture Volta de Nvidia, la re-convergence n’est pas exécutée par tous les threads concernés, elle est exécutée par chaque warp respectif puis demande un temps de synchronisation bloquant pour regrouper les warps.
Source: General-Purpose Graphics Processor Architecture
On retrouve aussi dans le GPU la même question que pour le CPU pour optimiser l’exécution de code : comment et dans quel ordre exécuter les warps ? En effet, les warps exécutent une seule instruction, mais comme dans CPU, est-il possible d’optimiser les exécutions ? Si on doit attendre qu’un warp finisse de s’exécuter pour en exécuter un autre, cela augmente considérablement la latence. Dans un monde utopique nous pouvons cacher cette latence en utilisant un système de multithreading à grain fin avec le même principe que le pipeline CPU : par exemple une fois l’IF finit, on refait une IF pour ne pas perdre de temps, mais cela demande au thread d’avoir ses propres registres, ce qui semble très coûteux. Mais si on augmente le nombre de warps cela diminuera le nombre de cœurs par puce et augmentera considérablement la taille du fichier de registre. Il y a aussi la solution du Cache-Conscious Warp Scheduling (CCWS) qui dit que lorsque les threads accèdent à des données disjointes, cela mène souvent à des structures de données complexes et qu’il serait mieux pour un thread donné d’être répétitivement sélectionné pour maximaliser la localité. La sélection de warps est problématique en terme d’optimisation.
Nous allons maintenant considérer 2 boucles, donc ajouter un nouveau niveau de sélection. C’est-à-dire que dans ces explications, nous allons ajouter le fait de ne pas savoir si l’instruction suivante est dépendante d’une ancienne instruction qui n’a pas fini de s’exécuter. Car si nous avons les informations sur l’information suivante, nous pourrions juste réduire le nombre de warps pour exécuter plus d’instructions. Pour se faire, les GPUs implémentent I-Buffer où les instructions sont placées après l’accès au cache, ceci aide à la détection des dépendances des instructions. Les CPUs utilisent un tableau de marque qui est un tableau de bit qui représente chaque opérande et sa complétion par rapport aux instructions non complétées, donc qui permet d’éliminer les dépendances de nom et introduit le besoin de logique associative, et des stations de réservation. Les GPUs utilisent une exécution « in-order » des tableaux de marque, ce qui permet d’éviter les problèmes de hasard sur read-after-write et write-after-write. Ceci est très simple d’implémentation sur un seul thread, mais sur un warp c’est différent. Avec au moins 128 registres par warp, et 64 warps par cœur, le tableau de marque demande 8192 bits pour être implémenté. Le problème d’une exécution multi-threadée « in-order » c’est qu’une fois une instruction complétée, les prochaines doivent sonder le tableau des marques, et sonder le tableau des marques nécessites au moins 4 opérandes, donc 256 lectures pour permettre à tout les warps de continuer, ce qui est très coûteux. Une solution alternative serait de réduire le nombre de warps qui peut sonder la table des marques à chaque cycle, ce qui réduirait le niveau de parallélisme. La solution la plus courante est de mettre un cardinal de la table des marques de 3 ou 4 et mettre en place une instruction NOR qui attend que chaque bit de la table des marques soit à 0 pour exécuter l’instruction.
Donc dans une architecture à deux boucles, la première boucle sélectionne un warp pour l’I-Buffer, vérifie le PC et accède à la prochaine instruction (située dans le cache). La seconde boucle sélectionne une instruction dans l’I-Buffer qui n’a (plus) aucune dépendance et l’ajoute à l’exécution. Donc le même warp est utilisé pour plusieurs opérations.
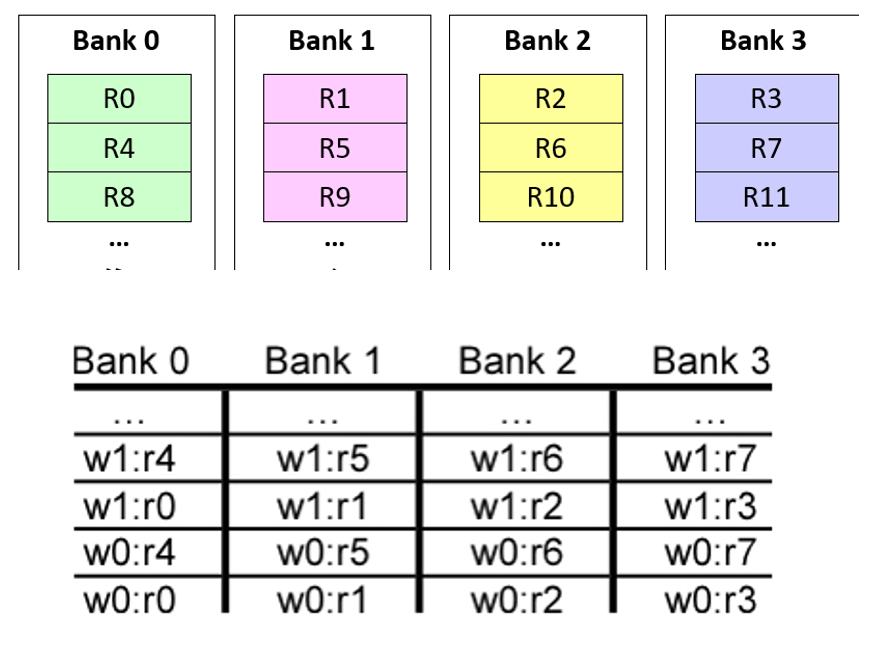
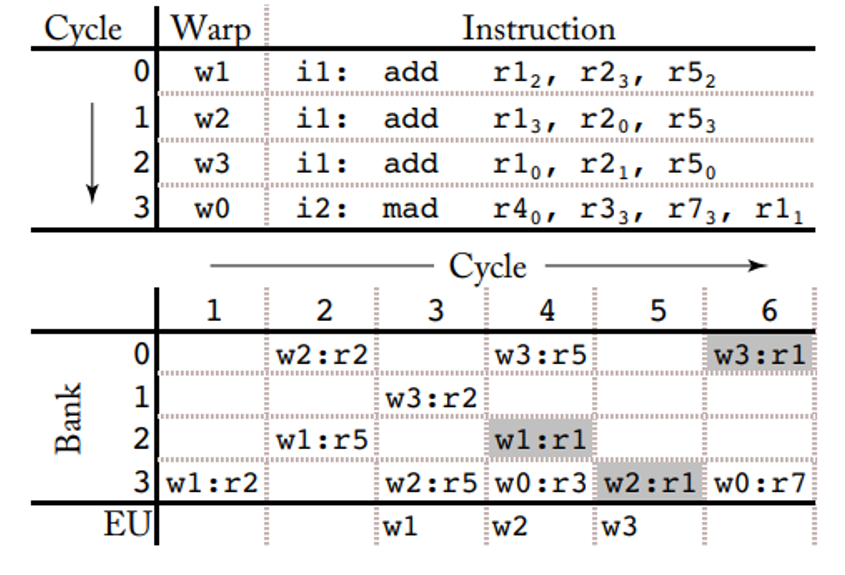
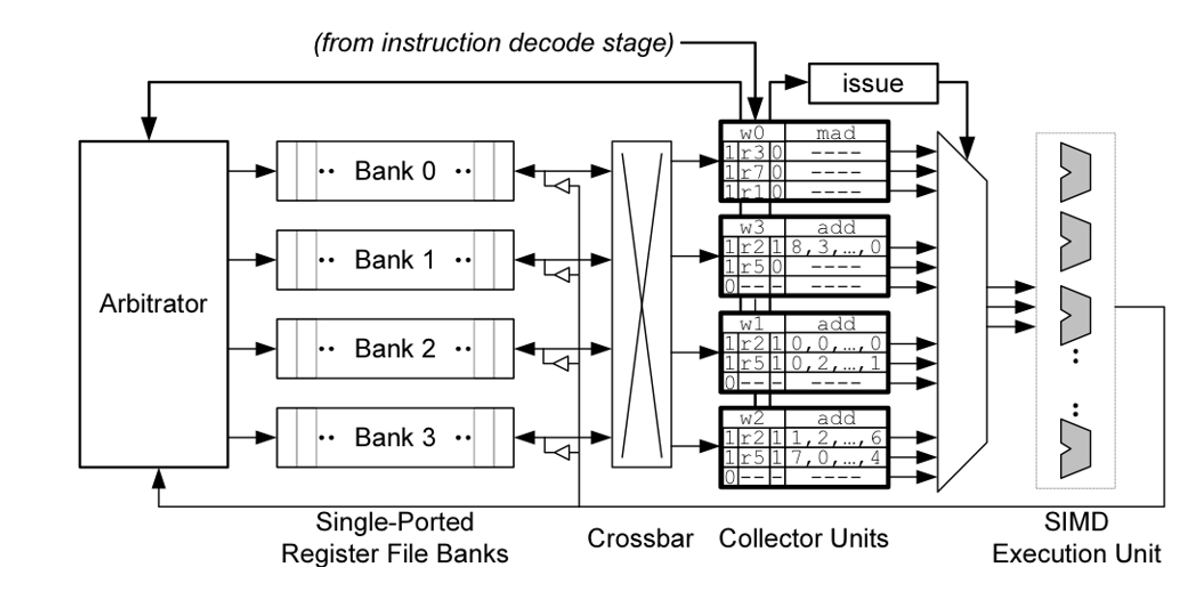
Désormais dans un système à 3 boucles : nous savons que pour cacher la latence GPU il est nécessaire d’avoir beaucoup de warps par cœur, et pour supporter cycle par cycle le switch de warp nous devons avoir un grand fichier de registre, de l’ordre de 256KB par exemple. L’implémentation naïve d’un fichier de registre nécessite un port par opérande par instruction émise par cycle. Une manière de réduire la taille du fichier de registre est de simuler un grand nombre de ports en utilisant des banques de mémoires à port uniques. On pourrait alors mettre ces banques dans l’ISA, mais dans certains GPUs cette structure est appelée Operand Collector, introduite par l’architecture Fermi de Nvidia.
Source: General-Purpose Graphics Processor Architecture

Source: General-Purpose Graphics Processor Architecture
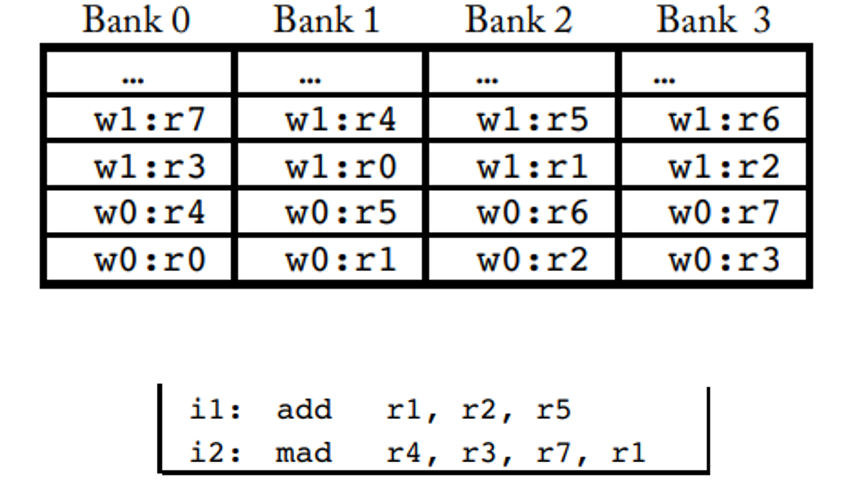
Le problème des banques c’est que lorsque l’on veut faire une opération qui demande par exemple une lecture sur R5 et R1, cela créer un conflit et donc demande 2 cycles pour accéder à ces données. Et si toutes nos opérations utilisent une seule banque, le principe de la banque devient inefficace.

Source: General-Purpose Graphics Processor Architecture
C’est là où l’OC rentre en jeu : il y a des unités de collections (CU) qui vont enlever ce conflit, leur principe est similaire à la station de réservation dans l’algorithme de Tomasulo : L’arbitre sélectionne les opérandes de sorte à ce qu’il n’y ait pas de conflits dans un cycle donné tout en considérant le write-back (WB). Le seul problème connu est qu’il n’y a pas d’ordre d’exécution entre les différentes instructions, et que ça peut engendrer le problème de write-after-read (WAR). Une solution est de permettre à seulement une instruction de collecter les opérandes dans l’OC un par un, ce qui, d’après les études, réduirait de 10% les performances de l’OC. Et pour proposer du parallélisme dans l’OC, ils suggèrent un « bloomboard » pour traquer les lectures de registres. Une analyse montre que du côté de l’architecture Maxwell de Nvidia, ils ont introduit une « barrière de dépendance à la lecture » gérée par des instructions de contrôles et qui permettraient d’éviter les hasards WAR pour certaines instructions.
Source: General-Purpose Graphics Processor Architecture
Source: General-Purpose Graphics Processor Architecture
Source: General-Purpose Graphics Processor Architecture
Dans le pipeline GPU il y a aussi des gestions de hasards structurels : par exemple l’étape de lecture de registre peut ne plus avoir d’Operand Collector Units (OCU). La majorité des hasards structurels sont reliées à la mémoire système, en général, une seule instruction mémoire exécutée par un warp peut être découpée en une multitude d’opérations et peut utiliser à son plein potentiel la portion du pipeline. Dans un pipeline CPU, la solution est de commencer à exécuter les instructions suivantes non dépendantes, mais dans un système multi-threadé ceci est moins apprécié pour deux raisons : la première, au vu de la taille du fichier de registre et du nombre d’étapes dans le pipeline GPU pour supporter un pipeline graphique peut impacter le chemin critique, la seconde, c’est que caler une instruction derrière un warp peut décaler les instructions d’autres warps en cas de synchronisation (comme sur l’architecture Pascal). Donc pour éviter ces problèmes, les GPUs implémentent une sorte d’instruction à rejouer, c’est utilisé dans certains CPUs pour réparer les prédictions spéculatives.
La suite ici !